What is clustering?
By this time, we are familiar with the notions of distance and similarity between a pair of points, and k-nearest neighbors of a given point.
The next natural analytic approach is to check if some points are grouped together in the data forming a neighborhood. Being able to detect such neighborhoods will help us find objects that have similar features.
The problem of automatically detecting neighborhoods in the data is called a clustering problem.
Commonly used input and output of a clustering algorithm
Input: A clustering algorithm takes the data points of a dataset as the input. Sometimes additional inputs are required depending on which clustering algorithm we use. We will discuss specific clustering algorithms in the upcoming lessons. For now, let us remember that the entire dataset is an input for any clustering algorithms.
Output: A clustering algorithm outputs several clusters, each composed of a subset of the data points provided in the data.
The basic clustering objective
The basic clustering objective is to construct clusters of points with low intra-cluster distance and high inter-cluster distance. Intra-cluster distance refers to the pairwise distance of the points in the same cluster. Inter-cluster distance refers to the distance between points in different clusters. The clustering objective is to create points of local clusters and at the same time clusters are separated as much possible.
In a good clustering outcome, the data points in the same cluster are highly similar and the data points in different clusters are highly dissimilar.
A simple example
Let us start with a simple example. Let us consider that we have the following two-dimensional dataset.
|
Feature 1 |
Feature 2 |
|
9 |
11 |
|
11 |
13 |
|
5 |
4 |
|
3 |
4 |
|
10 |
12 |
|
2 |
5 |
|
12 |
12 |
|
11 |
14 |
|
1 |
3 |
That means we can compute the distance between any pair of objects, or rows of this dataset. The distance measure is the basis of any clustering algorithm when forming the groups.We already know how to compute the distance between two rows or two data points using a distance measure like Euclidean distance or Manhattan distance.
Before we dive into the details of any clustering algorithm, let us discuss more on the clustering problem.
Our data has two features or two dimensions. That means, we can draw a two-dimensional plot to see how the points look like in the mathematical space the data creates.
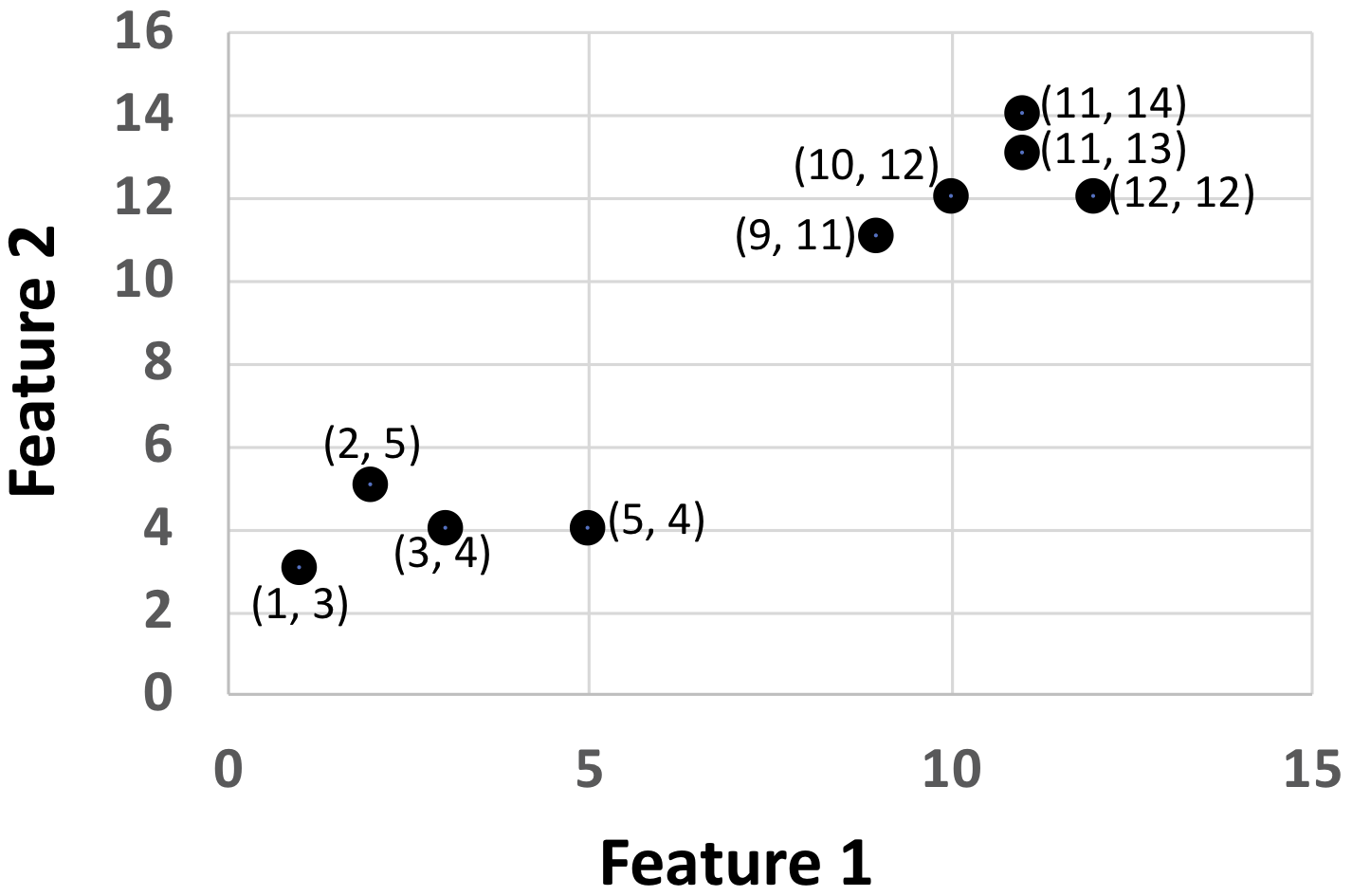
Now that we have a visual representation of the data, can we see how many groups of points are there? There are actually two groups. One group is on the lower-left group side and the other group is on the upper right side. The lower-left group has four data points and the upper-right group has five data points. Let us call the lower-left group Cluster 1 and upper-right group Cluster 2.
Given the data points and the plot above can we fill out the third column of the table with cluster IDs (Cluster 1 and Cluster 2)? Please fill out the third column, as a practice.
|
Feature 1 |
Feature 2 |
Cluster ID |
|
9 |
11 |
? |
|
11 |
13 |
? |
|
5 |
4 |
? |
|
3 |
4 |
? |
|
10 |
12 |
? |
|
2 |
5 |
? |
|
12 |
12 |
? |
|
11 |
14 |
? |
|
1 |
3 |
? |
The outcome of a clustering algorithm: The purpose of any clustering algorithm is to fill out a column (like the third column above) to state in which cluster each data point belongs.
In the example above, we can find out which cluster a point belongs to because we have a visual representation of the data through which we could easily see two groups. In high-dimensional datasets, we will not be able to plot the data because data with more than three dimensions does not have direct visual representations. Moreover, we may have millions of points in our data. Therefore, visual inspection for clustering is not an option for most datasets. This is why we need algorithms for clustering data points.
Analytical benefits of clustering data
Suppose a data analyst receives a dataset with millions of rows and tens of dimensions. It is hard to analyze the data without some domain knowledge. Since a data analyst might not have (and in most cases, they don’t) the domain knowledge to start synthesizing the data, she/he looks at the structure of the data by clustering it.
Clustering brings similar objects (rows) in the same group. That is, clustering is an abstraction of the data. It is easy to start from five clusters compared to directly analyze one million data points. Clustering is a mechanism to explore data when there is not much information regarding the data, or when a specific data analytic problem is not available.
6 Comments
Thanks for detailed explanation.
Thanks for the explanation
Nice one
Thank you!
Thanks kindly for providing such interesting knowledge
Thank you for visiting the page. I am happy to know that you enjoyed the content.