Distance measures
Given a pair of vectors (data points, or objects, or rows of a table), we can use some existing distance measures to compute how different or similar the vectors are. We will start with a distance measure that we are already familiar with from geometry — the Euclidean distance.
You might recall from geometry that the distance between two points 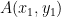

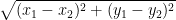
For example, consider Row 2 and Row 5 of the following table. Row 2 has (5, 4), and Row 5 has (9, 2). Therefore, the distance between Row 2 and Row 5 is equal to

| Feature 1 | Feature 2 | |
| Row 1 | 10 | 3 |
| Row 2 | 5 | 4 |
| Row 3 | 10 | 4 |
| Row 4 | 8 | 6 |
| Row 5 | 9 | 2 |
What happens when we have a three-dimensional dataset like the following one, instead of a two-dimensional dataset?
| Feature 1 | Feature 2 | Feature 3 | |
| Row 1 | 10 | 3 | 3 |
| Row 2 | 5 | 4 | 5 |
| Row 3 | 10 | 4 | 6 |
| Row 4 | 8 | 6 | 2 |
| Row 5 | 9 | 2 | 1 |
The principle of Euclidean distance is the same for a higher-dimensional space — the square root of the summation of squared differences in each dimension. That is, for a three-dimensional dataset or space, the distance between two data points 

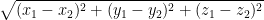
Row 2 of the table above contains (5, 4, 5) and Row 5 contains (9, 2, 1). The Euclidean distance between Row 2 and Row 5 of the data above is:
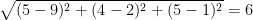
What happens if you have n-dimensional data?
| Feature 1 | Feature 2 | Feature 3 | Feature 4 | — | Feature n | |
| Row 1 | 10 | 3 | 3 | 5 | — | 10 |
| Row 2 | 5 | 4 | 5 | 3 | — | 6 |
| Row 3 | 10 | 4 | 6 | 4 | — | 9 |
| Row 4 | 8 | 6 | 2 | 6 | — | 3 |
| Row 5 | 9 | 2 | 1 | 2 | — | 11 |
Euclidean distance
Here is the general formula to compute the Euclidean distance between two data points or vectors, 


The formula can be generalized further:
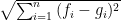
This formula to compute the distance between two points or vectors
Euclidean distance between 


Definitely, Euclidean distance satisfies the metric-properties or the four distance properties that we discussed earlier.
Manhattan distance
A simpler difference in every dimension can be computed without squaring the differences and without using the square root. That is, just sum up the differences between the two vectors in every dimension. The measure that just sums up the differences in each dimension of two points or vectors
Manhattan distance between

As an example, let us assume that we have a four-dimensional dataset. A pair of vectors in this dataset are: A=(5, 4, 9, 2) and B(4, 9, 2, 7).
Therefore, the Manhattan distance between A and B=

Manhattan distance satisfies the four distance properties that we discussed earlier.
What happens when there are strings
Things are simpler when data contains only numbers. Things become complicated when you have strings or text in your data cells. It might be difficult to imagine a Euclidean space with string data. Even if we cannot imagine a Euclidean space with strings, if we can come up with a distance measure that satisfies the four distance properties, then we have a Euclidian space.
In this document, we discuss two distance measures — hamming distance and edit distance — for strings.
Hamming distance
Hamming distance between two strings is the number of positions where the strings have different letters. Obviously, to be able to compute the Hamming distance between two strings, the strings must have the same length.
As an example, consider that we are computing the distance between the following two strings.
apricot
abrikop
The two strings are different in positions 2, 5, and 7. That is, they are different in three positions. Therefore,
Hamming distance (apricot, abrikop)=3
Hamming distance is sometimes used to compute the distance between binary bit vectors of the same length. Sometimes, binary streams are repeated during transmission to increase reliability. If the original binary message and the repeated one have a non-zero edit distance, it is confirmed that some bits were corrupted during the transmission. Of course, if both the bits in the same position are changed to the same bit, then the Hamming distance will not be able to capture the corruption.
Hamming distance is a true distance measure. That is, it satisfies the four distance properties.
Edit distance (LCS-based)
The edit distance between two strings refers to the minimum number of edits required to convert one string to the other. What do we mean by the “number of edits?” Edit refers to one of the two following tasks: delete or insert. That is, the edit distance between two strings is the minimum number of delete and insert operations required to convert one string to the other.
Please note that given an infinite number of edits it is always possible to convert one string to another. We are talking about the “minimum” number of edits.
As an example, consider that we have two strings S1 and S2.
S1=xyzmn
S2=yzmopn
Let us try to convert S1 to S2.
We have, S1=xyzmn
Delete x from S1. S1 is now yzmn.
Insert o in the fourth position. S1 now becomes yzmon.
Insert p in the fifth position. S1 now becomes yzmopn.
Notice that S1 has become S2=yzmopn.
To convert S1 to S2, we needed three edits (one delete and two insertions.) We cannot do this conversion with any lesser edits than 3.
Therefore, the edit distance between xyzmn and yzmopn is 3.
Edit distance is a true distance measure. Therefore, it holds all the four axioms required in a distance formula. As a result,
edit distance (S1, S2)=edit distance (S2, S1)
If you attempt to convert yzmopn to yzmon you will see that you need a minimum of 3 edits. (Please do it as an exercise.)
There is an alternative way to compute the edit distance. The alternative relies on the length of the longest common subsequence (LCS). The formula is:
edit distance(S1, S2) = |S1| + |S2| – 2 |LCS(S1, S2)|
|S1| or |S2| indicates the length of the corresponding string. |LCS(S1, S2)| is the length of the longest common subsequence between S1 and S2.
LCS refers to the longest sequence of letters that are present in both the strings from left to right. Let us take our example strings S1=xyzmn and S2=yzmopn. Notice that the yzm is present in both the strings from left to right. However, yzm is not the longest sequence that is present in both the strings from left to right. The longest sequence that is present in both the strings from left to right is yzmn.
Note here that to be a subsequence, the subsequence need not be a contiguous substring. The letters of the subsequence may appear in the same sequence in a given string. For example, although yzmn is a substring in |S1|, yzmn does not appear as a substring in |S2|. In |S2|, yzm appears at the beginning of the string and n appears at the end. Still, yzmn is considered a subsequence of |S2|. That is, a substring is a subsequence but a subsequence may not be a substring.
Therefore,
edit distance(S1, S2) = edit distance(xyzmn, yzmopn)= |xyzmn| + |yzmopn| – 2 |yzmn|=5+6-2*4=3
Notice that the LCS-based formula is giving us the same edit distance as before for the given pair of strings.
The LCS-based formula for edit distance is widely used because there are existing algorithms in the literature to compute LCS. Hence, computing edit distance is not difficult when someone uses an existing algorithm to compute LCS.
15 Comments
Hello Sir
The edit distance between S1=banana & S2, cbnaa
=3
Hello,
S1=banana
S2=cbnaa
The edit distance (banana,cbnaa)= 6+5_(2*4) =11_8=3
we have to,
delete “c”
and
insert “a” & “n”
I hope i got it right
That is correct! Thank you.
Thank you for such a explanation
I am glad to know that the explanation was useful. Thank you for visiting the page.
Hi,
Euc_D = 7.874008
Manh_D = 16
Edit_D(S1, S2) = 3
Thanks a lot for your excellent explanation.
These are all correct answers. Thank you for summarizing all the answers here.
Hi,
Edit_D(s1, s2) = 3.
Thanks a lot for your excellent explanation.
That is correct! Thank you for visiting and providing your feedback.
Eucd = 7.874008
Manhd = 16
These are correct answers. Thank you!
the Euclidean distance between raw 2 and raw 5 is 7.87
while the Manhattan distance is 16
….
while this is intuitive, I would love to know how this math came out because I don’t think I fully understand.
thank you very much for the knowledge you’re sharing.
Thank you for your comment. I did not explain more because it will increase the complexity of the video. It is great to hear that you are interested to know more about it. In practice, the distance measures discussed on this page are coming from geometry. The following wikipedia page will give you a little more explanation: https://en.wikipedia.org/wiki/Taxicab_geometry.
Thank you. Have a wonderful day.
Hello,
The euclidean distance between row2 & row5 = 7.874
Manhattan distance between row2 & row5 = 16
Edit distance (S1,S2) = 3
All of the three answers are correct! Thank you for solving them and sending the answers. Best regards.