Notions of “nearness”: distance and similarity
Given that you can place your data in the space, you can measure how near a point is to another in the space. The concept of nearness or farness in the space is known as proximity. Proximity is quantified in two ways: by computing distance or by computing similarity between two vectors (i.e., two data points.)
What is “distance”?
Distance refers to how far is a data point from another in the space. Given two vectors or two data points, you can always compute the distance. We will discuss a few distance measures soon. Before discussing how to calculate the distance between a pair of vectors, we need to explain what distance really means.
Many of us use the word “distance” when we are really referring to “dissimilarity.” It is not a big deal most of the time. However, it might be a big deal for many algorithm designers because certain algorithms require certain proximity properties to hold to function properly.
A distance formula must satisfy the four following axioms.
- D(p1, p2)≥0. This indicates that the distance between two points p1 and p2 cannot be negative.
- D(p1, p2)=0 iff p1=p2.
- D(p1, p2)=D(p2, p1). This indicates that the distance from a point p1 to p2 cannot be different than the distance from p2 to p1.
- D(p1, p2)≤D(p1, p3)+D(p3, p2). The distance from one point to another cannot be greater than the distance between the same two points via another point. This is commonly known as the triangle inequality property — the length of one side of a triangle cannot be greater than the sum of the other two sides.
If I come up with a distance measure that does not satisfy the fourth property, but the three other properties are satisfied, I will not be able to call it a “distance” measure; instead, I should call it a “dissimilarity” measure. When coming up with a new distance measure, the fourth property is the one that is the hardest to satisfy.
Why do we need to study distance or similarity measure?
“Proximity” is the key to many data science problems. Many data science algorithms somehow rely on the space created by the data and how close or far data points are from one another to recognize or discover patterns in the data. This is the reason why we learn distance and similarity measures at the beginning of a data science course.
We might have a dataset with one hundred columns and ten thousand rows. Given a row (that is, a vector, or a data point, or an object), how can we find the rows that look similar to the given row? The problem is called finding the nearest neighbors of a given data point.
Given a large dataset of five thousand columns and one million rows, how can we group rows that have similar values? This problem is commonly called a clustering problem.
There are many other types of data science problems for which computing distance or similarity is a building block of the respective solutions.
What is the relationship between distance and similarity?
A large distance between two data points refers to a small similarity between them. A small distance indicates high similarity. Therefore, similarity and distance are two opposite measures to quantify proximity.
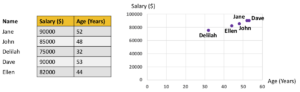
Let us get back to the data above. The data table is at the left, and the corresponding space composed of two features, Age and Salary, is at the right. Notice in the table, that Jane and Dave have the same Salary (90K) and almost the same Age (52 and 53.) As a result, the corresponding points for Jane and Dave in the space drawn at right are close, indicating high similarity between the objects or small distance between the points.
The rows for Delilah and Dave are quite different. That is, the rows have low similarity. That also means that the data points have a high distance in the space, as observed in the plot at the right.
11 Comments
Really, great content sir, I love the content how are you explained.
I am glad to hear that you found the content useful. Thank you for visiting.
Thanks. You make learning so interesting! Speed and clarity of content delivery is excellent!
Thank you for your kind words. Have a wonderful rest of the week.
Hello. I am one of the subscribers for your Data Science course.
Thanks for making it so interesting and simple. I am enjoying learning
I am glad to hear that you are enjoying the content. I will make sure to create more content in this Data Science series. Thank you for visiting the website and commenting.
Thanks for the clarity Sir. Look forward building a relationship because I am interested deeply in this course.
Why do you say that Jane and Dave have almost the same salary?
Hi David,
Actually I was referring to “almost the same salary and age”. Although they earn equal amount of salary their ages are slightly different leading to the word “almost”. Sorry for the confusion. I have now changed the sentence to “Jane and Dave have the same Salary (90K) and almost the same Age (52 and 53.)” Thank you for bringing this to my attention.
Best regards,
Shahriar
Great Lesson!
Thank you so much for visiting and commenting!