Similarity measures and their Python implementations
The high similarity between a pair of points indicates that the points are nearby. Low similarity indicates a large distance. Literature covers several similarity measures.
Jaccard index or Jaccard coefficient
Jaccard index/coefficient/similarity is generally computed between two sets of items. It is a ratio of commonality between the sets over all the items. If X and Y are two sets, then the Jaccard index between two sets is computed using the ratio of the size of the intersection and the size of the union of the two sets.

If X={a, b, c}, and Y={b, c, d, e} then, the size of the intersection between X and Y is:

and the size of the union of X and Y is:
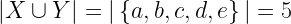
Therefore, for given X={a, b, c} and Y={b, c, d, e}:
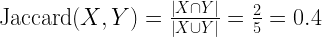
Jaccard similarity varies between 0 to 1. A value of zero indicates no similarity between the two sets at all. A value of 1.0 indicates that the two sets are the same.
Weighted Jaccard index/coefficient/similarity
Jaccard index can be computed between two vectors too. Jaccard index computed between two vectors/data points/objects is called a weighted Jaccard index. Given X and Y — two vectors each of length n — the formula for weighted Jaccard index or similarity between them is:

Suppose, we have a four dimensional dataset (Features 1 through 4).
| Feature 1 | Feature 2 | Feature 3 | Feature 4 | |
| Row 1 | 10 | 3 | 3 | 5 |
| Row 2 | 5 | 4 | 5 | 3 |
| Row 3 | 9 | 4 | 6 | 4 |
| Row 4 | 8 | 6 | 2 | 6 |
| Row 5 | 20 | 15 | 10 | 20 |
Let us compute the Jaccard similarity between Row 1 and Row 3.
Row 1 contains (10, 3, 3, 5). Row 3 contains (9, 4, 6, 4).
Weighted Jaccard similarity between Row 1 and Row 3 is:
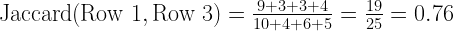
Let us compute the Jaccard similarity between Row 1 and Row 5.
Row 1 contains (10, 3, 3, 5). Row 5 contains (20, 15, 10, 20).
Weighted Jaccard index between Row 1 and Row 5 is:

That means Row 3 is more similar to Row 1 than Row 5.
Weighted Jaccard similarity may vary between 0 and 1.0. A value of 1.0 indicates that the two vectors are the same. A value of 0 indicates no similarity between the two vectors.
Notice that the set-based Jaccard similarity we discussed earlier in this lesson is a special case of weighted Jaccard similarity — in the set-based Jaccard similarity, the weight of an item (feature) can be either 1 (present) or 0 (absent.)
Cosine similarity
Cosine similarity between two vectors X and Y is computed using the following formula.

X.Y is the dot product of two vectors, each of length n.
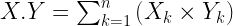
||X|| refers to the L2-norm of a vector X that has a length of n.

Hence, 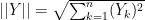
Example: Consider Row 1 and Row 3 of the four-dimensional data table above. Row 1 contains (10, 3, 3, 5) and Row 3 contains (9, 4, 6, 4). What is the cosine similarity between Row 1 and Row 3?
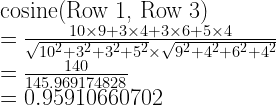
Now, compute the cosine similarity between Row 1 and Row 5. Row 1 contains (10, 3, 3, 5). Row 5 contains (20, 15, 10, 20). The cosine similarity should be 0.93494699.
Therefore, Row 3 is more similar to Row 1 than Row 5.
Cosine similarity may vary between -1 to 1. However, it is widely used in the positive space. In the positive space, the similarity varies between 0 to 1. It is specially used in the positive space for document datasets where document vectors have positive numerical values. Hopefully, we will discuss more on document-vectors in the future.
Also, note that if one of the vectors, when computing cosine similarity, contains all zeros, cosine similarity will give a division-by-zero error. An assumption here is that the origin (0, 0, …, 0) is not a data point in the data.
Tanimoto coefficient/index/similarity
Tanimoto similarity between two vectors X and Y is computed using the following formula.
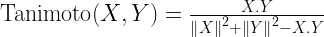
Example: Consider Row 1 and Row 3 of the four-dimensional data table that we have been using in this lesson. Row 1 contains (10, 3, 3, 5) and Row 3 contains (9, 4, 6, 4). What is the Tanimoto index between Row 1 and Row 3?

Now, compute the Tanimoto similarity between Row 1 and Row 5. Row 1 contains (10, 3, 3, 5). Row 5 contains (20, 15, 10, 20). Please do the calculation as a practice. You will find that Tanimoto between Row 1 and Row 5 is 0.419932811.
Row 1 has a larger Tanimoto similarity with Row 3 than Row 5. Therefore, Rows 1 and 3 are more similar than Rows 1 and 5.
Python code to compute similarity between two rows
Here is a code sample containing functions for Jaccard, Cosine, and Tanimoto similarities.
import numpy as np
def jaccard (vec1, vec2):
minimum=[]
for i in range(0, len(vec1)):
minimum.append(min(vec1[i], vec2[i]))
maximums=[]
for i in range(0, len(vec1)):
maximums.append(max(vec1[i], vec2[i]))
j=sum(minimum)/sum(maximums)
return j
def cosinesim(vec1, vec2):
numerator = np.dot(vec1,vec2)
v1norm= np.sqrt(sum(vec1**2))
v2norm= np.sqrt(sum(vec2**2))
c = numerator/(v1norm*v2norm)
return c
def tanimotosim(vec1, vec2):
numerator = np.dot(vec1,vec2)
v1norm= (sum(vec1**2))
v2norm= (sum(vec2**2))
t = numerator/(v1norm+v2norm-numerator)
return t
rawdata = [[10, 3, 3, 5],
[12, 13, 20, 7],
[1, 1, 2, 7],
[8, 1, 2, 7],
[2, 1, 2, 7],
[10, 3, 3, 5]]
data = np.array(rawdata)
r1=0
r2=3
jacc = jaccard(data[r1], data[r2])
print("Jaccard similarity between rows ", \
r1, "and",r2,"is")
print(jacc)
cos = cosinesim(data[r1], data[r2])
print("Cosine similarity between rows ", \
r1, "and",r2,"is")
print(cos)
tanimoto = tanimotosim(data[r1], data[r2])
print("Tanimoto similarity between rows ", \
r1, "and",r2,"is")
print(tanimoto)
Concluding remarks on the similarity
Our focus in this lesson was similarity measures between two vectors (and also two sets.) Any data that can be represented in tables can leverage the similarity measures explained in this lesson. Many other similarity measures may exist for different types of data. For example, there are graph similarity measures for graph data. Time series data may have other similarity measures too.
Why are we discussing distance and similarity measures? Distance or similarity measures are the core of many data science and artificial intelligence algorithms. We will use some of the distance and similarity measures in some of the algorithms, in this course.
6 Comments
It’s much confusing oo but I’m trying to get it
I hope this will start to feel easier with multiple iterations of the same content. Thank you for watching.
Exceptional teaching technique, Salute.
I appreciate the kind words. We will create more videos in the coming months. Please stay tuned.
Thanks. This section was challenging.
I am glad to hear that you have completed this section. Thank you!