: Numpy, Pandas, scikit-learn")
Data Science Workshop 1 (Part 1): Numpy, Pandas, scikit-learn
Hi I am Dr. Shahriar Hossain. I am running a data science workshop series for a small group of experienced professionals who have at least a computer science degree. Some of them have business and administration backgrounds. All of the participants have more than a decade of experience in the software and information technology industry. Most importantly, all of them are interested in knowing more about basic data science techniques.
Since the participants are already proficient in multiple programming languages, my objective for this workshop is to demonstrate the capabilities of the data science packages already available with python programming. When required, I give a brief description of an algorithm and the theory behind it, and then I quickly move forward to the coding part because this audience is tech-savvy and does not need the gory details of many of the items.
To maintain the participants’ privacy, I have removed all my discussions with them. I created a voiceover for these videos.
Here is the video for Workshop 1 Part 1.
Let us see what we discussed in the workshop.
Contents
Some Widely Used Data Science Python Packages
Python has ample packages to help data scientists, analysts, and practitioners dig into large datasets. We are starting with Numpy, Pandas, and scikit-learn in this workshop series.
Numpy and Pandas provide the basic functionality of data preprocessing. One can say that these two packages — Numpy, and Pandas — help in processing and exploring data programmatically. Instead of using Excel-like spreadsheet software, one can use Pandas to explore and clean data before applying any machine learning algorithm.
The package scikit-learn provides a rich suite of machine learning algorithms.
Tensorflow is another widely used machine learning library developed by the Google brain team.
Pytorch is another such package for machine learning. Facebook developed it.
If anyone starts to work on neural-network-based projects, I would recommend Tensorflow because it is widely used, and a lot of documentation and community forums are already available to seek help.
I would also note that PyTorch is also growing quite fast. It will likely be more popular in the coming years.
I summarized all these packages, including more, in another article.
For the workshop, I went over Numpy, Pandas, and scikit-learn, with coding examples.
Numpy
NumPy provides a flexible data structure with basic mathematical operations. An arbitrary number of dimensional arrays can be handled using NumPy. NumPy is a popular library for keeping data in multidimensional arrays.
The Pandas library is built on top of Numpy to help explore and preprocess data.
We need to bring our data to tabular form.
I should mention here that most of the prepackaged data science algorithms available with the libraries will require data in tabular form. In a separate article and video, I explained more about tabular data.
We have to bring our data to tabular form before we can apply these tools. If we have text documents, we have to make sure that we convert the documents to tabular form. One example of converting text data to tabular form is that each row of the table represents one document. Each column shows how many times a word was found in that document.
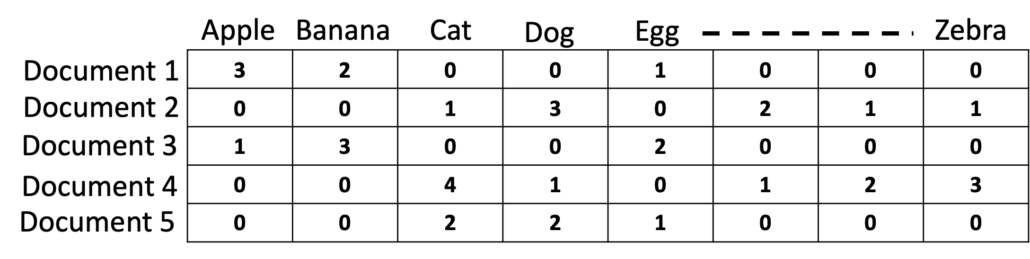
In reality, converting text documents to a tabular form is much more complex, but I am just giving a simple example here to clarify the concept. The summary is, we need tabular data to make sure that we can use many of the algorithms already available with the packages. NumPy helps us in keeping the tabular data in the main memory and apply mathematical operations.
Starting with Google Colab
To demonstrate examples of NumPy, I used Google colab. The website colab.research.google.com provides a Python editor. For this workshop, I used Google collab. The use of Google colab is convenient because the audience can easily practice what we are discussing without worrying about having Python to be installed on the local computer.
As a regular Python list, I am creating a variable named list1, which contains 5, 2, 10, and 3. Since Python is an interpreter, I can run code line by line. From a line in Google colab, I press Shft+Enter, or Shift+Return on MacBook to execute that line.
list1 = [5, 2, 10, 3] print(list1)
To see the content, I can simply type list1, and then press Shift+Enter to see what the content of the variable list1 is. If you are using Jupyter Notebook, another popular editor, you will have a similar style. If someone is using a regular Python editor like Spyder, then actually, you will have to use the print function to print the content of a variable, like list1. Notice that the entire array content is printed.
Anyway, this variable list1 is a list variable. Now, I want to create a NumPy variable. Let us import the package NumPy as np. Therefore, I can use this variable np to call NumPy functions.
import numpy as np arr1=np.array(list1)
I can create a NumPy array that will copy all the elements from list1. I use np.array and in parenthesis, I can provide the Python list I already have. I will save this newly created NumPy array in a variable named arr1.
1 Comment
Salman110