: Machine Learning Jargon")
Data Science Workshop 2 (Part 2): Machine Learning Jargon
Hi, This is Dr. Shahriar Hossain. I will go over an unsupervised learning algorithm using Python programming language soon. While explaining unsupervised machine learning to the audience, I figured that some terms are confusing for people who have just recently started to learn machine learning and data science. The most widely used terms are datasets, features, dimensions, attributes, and objects.
Before I jump into unsupervised machine learning, I need to quickly explain some of the terms we frequently use in machine learning and overall data science. That is, in this video, I am explaining popular data science jargon.
Here is the YouTube video where I explain popular machine learning and data science jargon.
What does a dataset mean?
A dataset practically means anything that represents data. You may have ten thousand images. You can call it a dataset.
You may have your bank statements and credit card statements in a folder. You can call that folder another dataset.
You may have a dataset containing 1 million text documents.
You have a list of product descriptions and the reviews just like what Amazon has. Is this a dataset? The answer is yes.
You may have multiple types of connected items in a dataset. In the same dataset, you may have images, comments against your images, product descriptions, and many more related items.
A dataset may be composed of video files, location, comments, and information on likes and dislikes about the video footages.
Therefore, the word, dataset, refers to a whole set of data where you may have many types of information, but all those information pieces must be somehow connected. In summary, a dataset is a collection of data.
Now, let us talk about a data table.
A data table is a data format where each row represents a unit of the data, and each column characterizes the unit of data. What does that mean? You are familiar with spreadsheets like excel. There are tables in Excel files.
Suppose, if you have a table of employees. A convention is to keep each employee in a row. Each column explains an employee. For example, the data piece “John” is a combination of his salary, number of running projects, and number of completed projects.
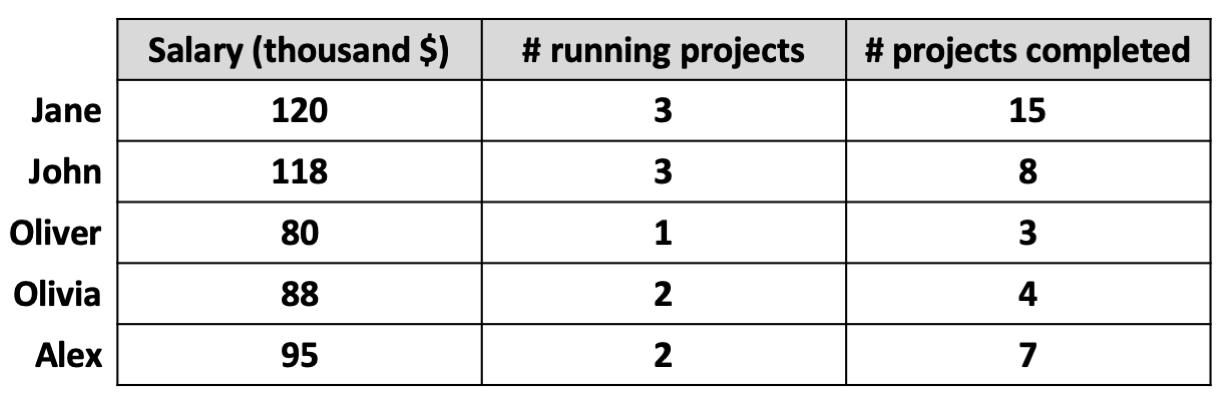
What is an object in the data science context?
An object in a data table or tabular data is the smallest unit of data. In this example, each employee is an object. For example, data associated with John is an object. Jane is considered the name of another object in this example.
A general convention is to keep the objects of a data table in rows.
What is a data point?
You might have heard the phrase, “a data point”.
A data point is nothing but an object. That is,
a data point = an object = a row of the data table.
Why is an object or a row called a data point?
The reason why we call a row or an object a data point is, a data table forms a mathematical space of the number of dimensions equal to the number of columns you have in the data.
In this example, you have three columns. Therefore, you can draw a three-dimensional mathematical space where a point can be drawn for each row or object.
This is the reason why an object or a row of a data table is also called a data point.
What is a feature?
Features are elements to characterize objects. In tabular data, features are generally kept in columns. Each column of a data table is a feature.
In this example, to characterize each object, we have three features —
salary, number of running projects, and number of completed projects. The features are kept in columns in a table as a convention.
Therefore,
Another name of the term “feature” is “attribute.”
That is,
You might have heard the word “dimension” in the data science and machine learning context.
What is a dimension?
A dimension is nothing but a feature in the context of data science. In our running example, this table is three-dimensional because it has three features. Remember, we can construct a three-dimensional space with this table of three features. This is the reason why features or columns, or attributes are also called dimensions.
That is,
What does the term “high-dimensional data” mean?
You already know that the word dimension refers to columns or the features of a dataset. Therefore, the phrase “high-dimensional data” means a data table with a high number of dimensions or features. That means if you have many dimensions or columns in your data table, you can call it a high-dimensional dataset.
Now, the question is, how many dimensions are good enough to call a data table high-dimensional?
There is no specific number on the definition of how many features you need to call your dataset high-dimensional. One thing to note here is that you cannot directly visualize the mathematical space created by your high-dimensional data. The reason you cannot visualize high-dimensional space is because of how we see things. We cannot see anything more than three dimensions.
If this table had four columns or five columns, we could not draw the mathematical space because we cannot draw a scatter plot of more than three dimensions. The mathematical space exists for higher dimensions than three, but we cannot just visualize it directly.
In this sense, a number of features starting from four can be called high-dimensional. However, even having several hundred columns or features might not be considered high dimensional in modern machine learning because the term “high-dimensional” sometimes refers to computational difficulty.
Some people say that a data table is high-dimensional if you have more features than objects. In my opinion, it is alright to keep some definitions vague and let those definitions evolve as computational capacity keeps rising.
Feature engineering
The steps involved in creating the columns or the features of a data table from raw data are called feature engineering. Some may call feature engineering preprocessing.
Most algorithms in machine learning take data in tabular form. This is the reason why we generally convert a non-tabular dataset into data tables. An example of a non-tabular dataset is text data.
I was using these terms — datasets, features, dimensions, and objects in the workshop. These are confusing terms for many. This video answers some of the questions that the audience asked me during the workshop session.
We will now create a dataset using which we will learn unsupervised machine learning. We are going to use the scikit-learn Python package for our coding. scikit-learn is a popular machine learning library for the Python programming language. It contains ample functions for supervised and unsupervised machine learning.