Multinomial Naive Bayes classification
Multinomial Naive Bayes is a popular classification algorithm in machine learning, commonly used in natural language processing (NLP) and text classification tasks. It is based on the Bayes theorem and the assumption of independence among features (generally, words of documents). In particular, it assumes that the probability distribution of each feature given the class label is a multinomial distribution. Given a document and a set of pre-defined classes, the algorithm calculates the conditional probability of each class given the document, and assigns the document to the class with the highest probability. Multinomial Naive Bayes is known for its simplicity, efficiency, and good performance on high-dimensional and sparse datasets, making it a popular choice for many text classification tasks.
The probability of document d belonging to a class c using a Multinomial Naive Bayes model

where:
is the posterior probability of class c given document d. The posterior probability is the probability of a class given a set of observed features. It is calculated by taking into account the prior probability of the class as well as the likelihood of the observed features given the class. The posterior probability for a class is used to determine the class of a new document.
is the prior probability of class c. Prior is the probability of a particular class in the training set. It is commonly calculated by dividing the number of documents belonging to a particular class by the total number of documents in the training set. The prior is used as an input to the classification algorithm to calculate the posterior probability of a class given a certain set of features. The prior can be thought of as a prior belief about the class of the document being classified. Prior is also referred to as bias. Bias is the tendency to favor specific outcomes over others or to prefer certain classes of objects over others.
is the conditional probability of word
given class c. Conditional probability is the probability of one event, given the occurrence of a second event. For example, the conditional probability of event A, given event B, is the probability of event A occurring, provided that event B has already occurred. This concept helps calculate the likelihood of a word given a particular class.
is the number of times word
is the total number of unique words in document d
The Maximum a Posteriori (MAP) is a standard method for making a classification decision using a probabilistic model, such as the Multinomial Naive Bayes model. Given the observed data, the MAP decision rule chooses the class that maximizes the posterior probability. In other words, given a document with a set of features (such as the occurrence of words in the document), the MAP rule selects the class that has the highest probability of generating those features. This approach balances the prior probability of each class (based on the distribution of classes in the training data) with the likelihood of observing the features given each class. The MAP rule is often used in text classification tasks, where the goal is to assign a category or label to a document based on its contents.

where 
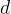
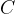
The product of many probabilities, often required when calculating the likelihood of a document given a class, can result in very small values, especially when dealing with large vocabularies or long documents. This can lead to numerical underflow, where the product becomes too small to be represented accurately by the computer, and may lead to incorrect results or errors in the calculation.
Taking the logarithm of the probabilities allows us to convert the product into a sum, which is more numerically stable and less prone to underflow. Additionally, the use of logarithms can simplify calculations since we can use addition instead of multiplication. Therefore, we can compute log probabilities instead of regular probabilities and avoid numerical issues while maintaining the same ranking of classes.

To obtain the actual probability values back for each word, we can exponentiate the log probabilities at the end of the computation.
In the Multinomial Naive Bayes model context, 

Without any information about the document, the prior probability can be used as a starting point to predict the class of a new document. For example, if the training set has 100 documents, and 30 belong to class
In the Multinomial Naive Bayes model, the prior probability is combined with the conditional probabilities of each feature (e.g., word) given the class to compute the posterior probability of the class given the document, as described by Bayes’ theorem. The prior probability balances the impact of the observed features, especially when there is little information about a particular feature in the document or when there are many possible classes.
In practice, the prior probabilities are usually estimated from the training data, either by counting the frequency of each class or by using more sophisticated techniques, such as maximum likelihood estimation or Bayesian estimation.
The formula for prior probability based on the class ratio in the training data can be written as:
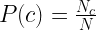
where:
is the number of documents in the training set that belong to class
is the total number of documents in the training set
In other words, the prior probability of a class
For example, if a training set contains 100 documents, with 30 belonging to class

In the Multinomial Naive Bayes model, the conditional probability of a word

where:
is the number of times word
is the vocabulary or the set of unique words in the training set
is the total count of all words in class
This formula computes the frequency of a word in a class as the number of times it appears in documents of that class, divided by the total count of all words in that class. This gives an estimate of the probability of observing a particular word in a document of a given class based on the frequency of that word in the training data.
Note that there is a possibility that the conditional probability of a word given a class
Laplace smoothing works by adding a small amount (typically 1) to the count of each word in each class, which slightly increases the probability of each word. Laplace smoothing is also known as add-one smoothing. It is called “add-one” smoothing because it involves adding one to the count of each word in each class. This technique is used to avoid the problem of zero probabilities that can arise when a word does not appear in training set for a given class.
Specifically, the formula for the conditional probability of a word given a class is modified to:

where |V| is the number of unique words in the vocabulary and |c| is the number of words in class c. That is |c| is the summation of all the lengths of the documents in class c.
Note that other smoothing techniques can be used in place of Laplace smoothing, such as Lidstone smoothing, which involves adding a small fraction to the count of each word instead of one, or Good-Turing smoothing, which estimates the probability of unseen words by extrapolating from the frequency of words that appear a few times in the training set.
Example
Let us say that we have the following documents with the words.
Document 1: apple apple banana
Document 2: banana orange
Document 3: banana apricot banana
Document 4: banana cat dog cat
Based on the given four training documents, the vocabulary V={apple, banana, orange, apricot, cat, dog}
Let us compute the words’ conditional probabilities considering that Documents 1, 2, 3 belong to Fruit class and Document 4 belongs to Canine class.
Prior probability, P(Fruit)=3/4=0.75.
Prior probability, P(Canine)=1/4=0.25.
We construct the following table to compute the conditional probabilities for each word using Laplace smoothing.
| Class | Word | count(wi, c)+1 | |V|+|c|=
Σw ∈ V(1+count(w, c)) |
P(wi|c) |
|---|---|---|---|---|
| Fruit | apple | 2+1=3 | 14 | P(apple|Fruit)=3/14=0.214 |
| banana | 4+1=5 | 14 | P(banana|Fruit)=5/14=0.357 | |
| orange | 1+1=2 | 14 | P(orange|Fruit)=2/14=0.143 | |
| apricot | 1+1=2 | 14 | P(apricot|Fruit)=2/14=0.143 | |
| cat | 0+1=1 | 14 | P(cat|Fruit)=1/14=0.071 | |
| dog | 0+1=1 | 14 | P(dog|Fruit)=1/14=0.071 | |
| Canine | apple | 0+1=1 | 10 | P(apple|Canine)=1/10=0.1 |
| banana | 1+1=2 | 10 | P(banana|Canine)=2/10=0.2 | |
| orange | 0+1=1 | 10 | P(orange|Canine)=1/10=0.1 | |
| apricot | 0+1=1 | 10 | P(apricot|Canine)=1/10=0.1 | |
| cat | 2+1=3 | 10 | P(cat|Canine)=3/10=0.3 | |
| dog | 1+1=2 | 10 | P(dog|Canine)=2/10=0.2 |
The table above contains the conditional probability of each word given a class – Fruit or Canine.
Now that we have the prior probabilities and conditional probabilities of all the classes, we can compute the probability/score that a new document belongs to either Fruit or Canine class using and then take the greater to classify the new document. That is, we can compute
Let us say that we have the following new document, d , for which we do not know the class label.
cat dog dog cat banana apple apple cat
What will be the predicted classification?
We will compute P(Fruit|d) and P(Canine|d). Then based on which one is higher, we will decide on the class label.
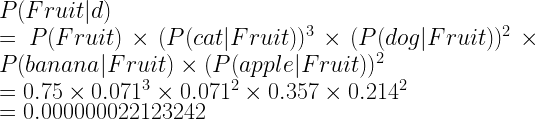
and

Given that 